

那是一个月黑风高、风雨交加、伸手不见五指的黑夜,冥冥之中好似要发生点什么
因为出了个"意外"再加上疫情原因,我一度变成了"植物人",差点去了二次元,好在"抢救"回来了。这几年找我的消息我也收不到了,感谢那些还在和关心我的人,谢谢。
错的并不是我,而是这个冥冥之中注定的世界
这些年找我的人和事,我也全部不知道,QQ、微信一些消息太久也都收不到了
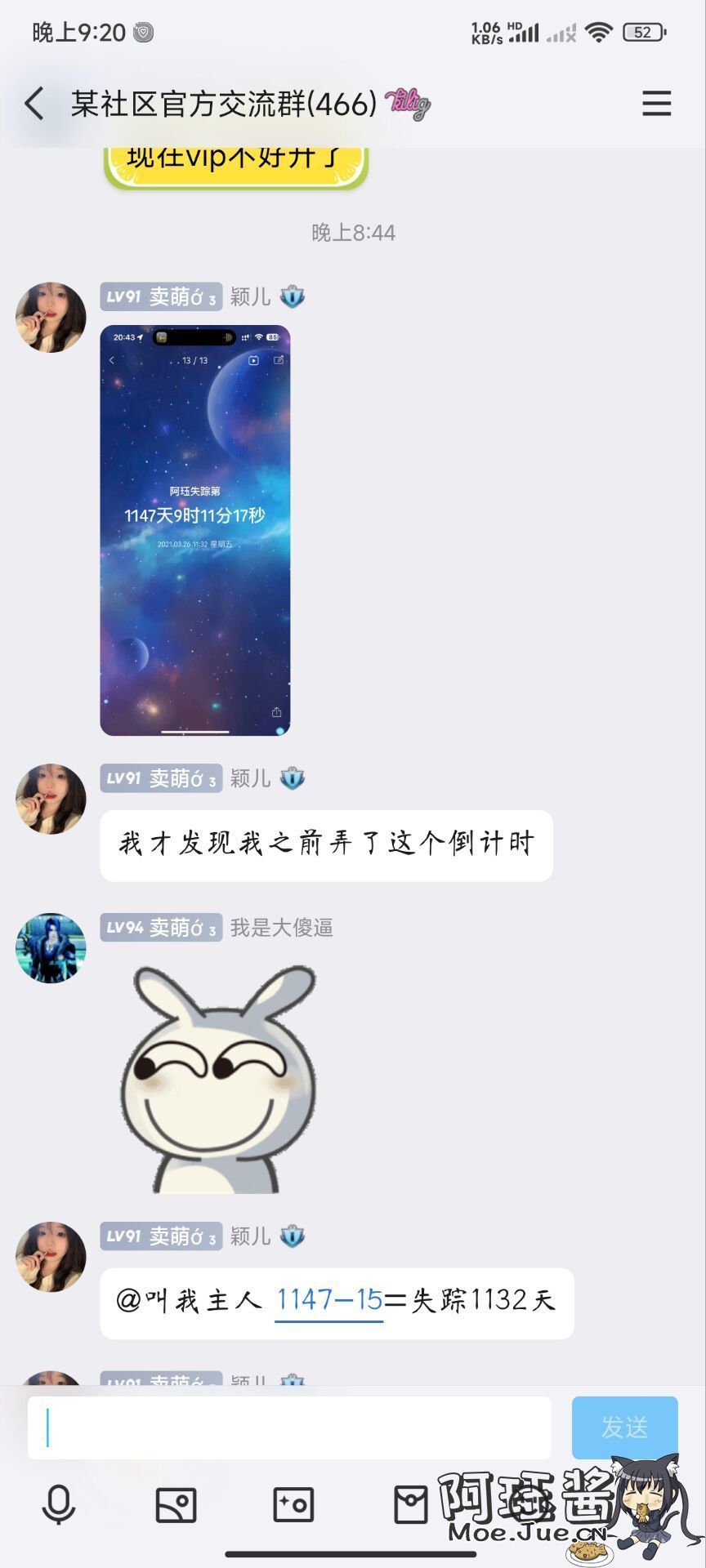
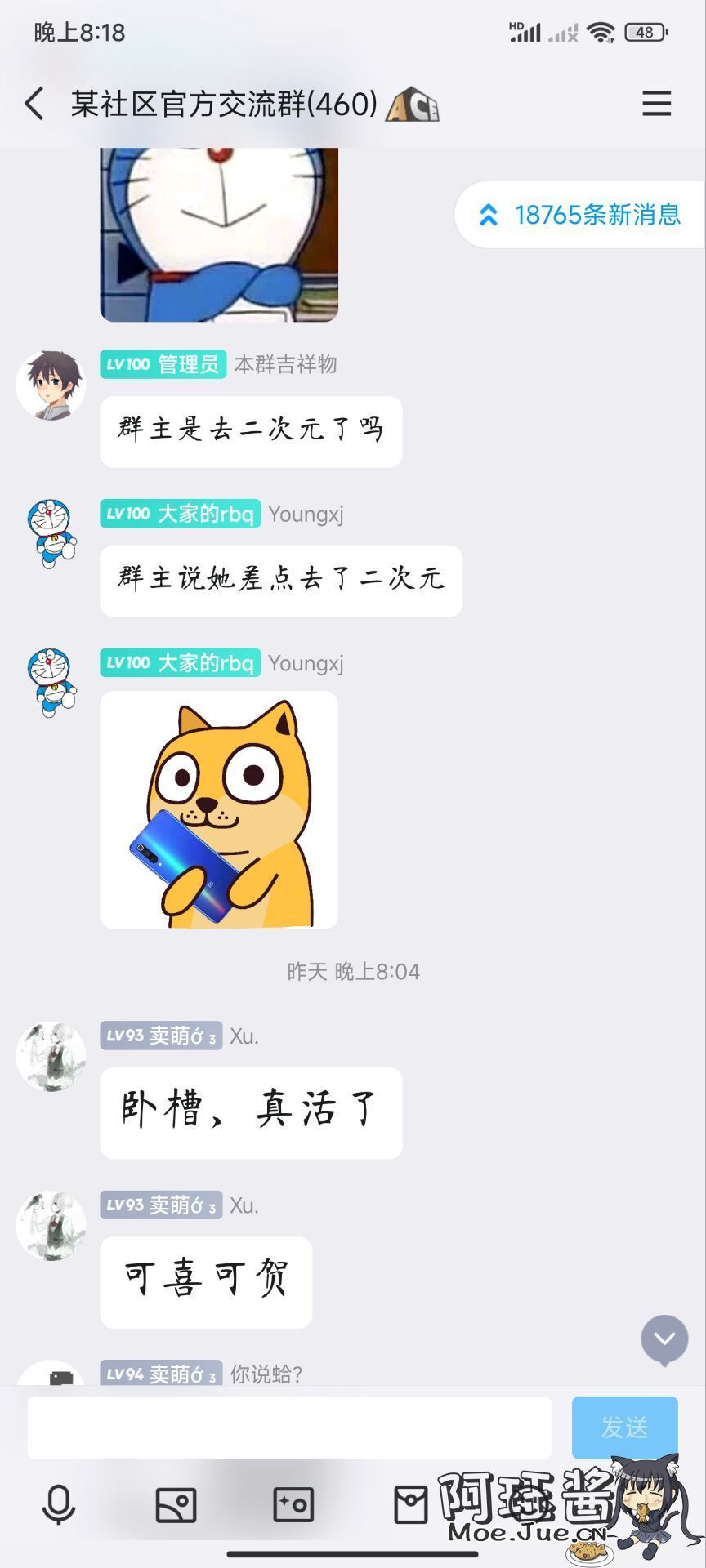
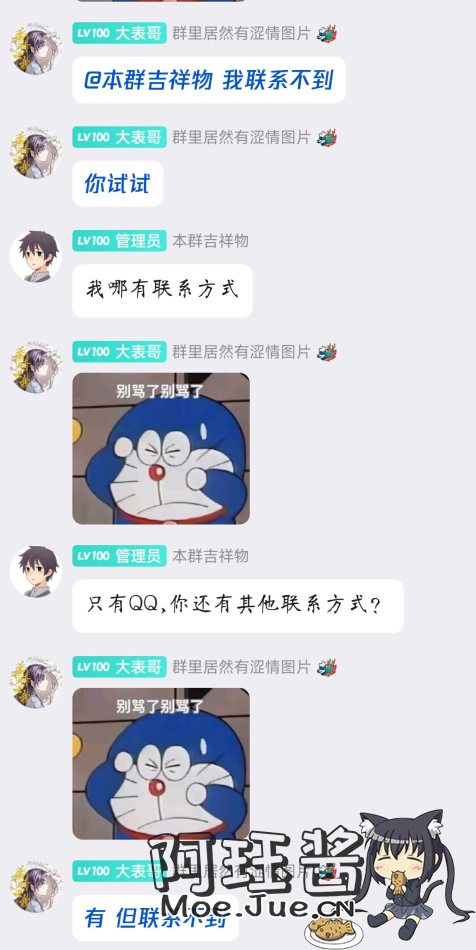
看到我多年未亮起的头像重新亮了起来,不少朋友都来问我怎么回事。
很感谢那些素未谋面的网友,或许叫朋友更亲切些,你们还一直惦记着我,让我很是感动。
一找就是找了我三年
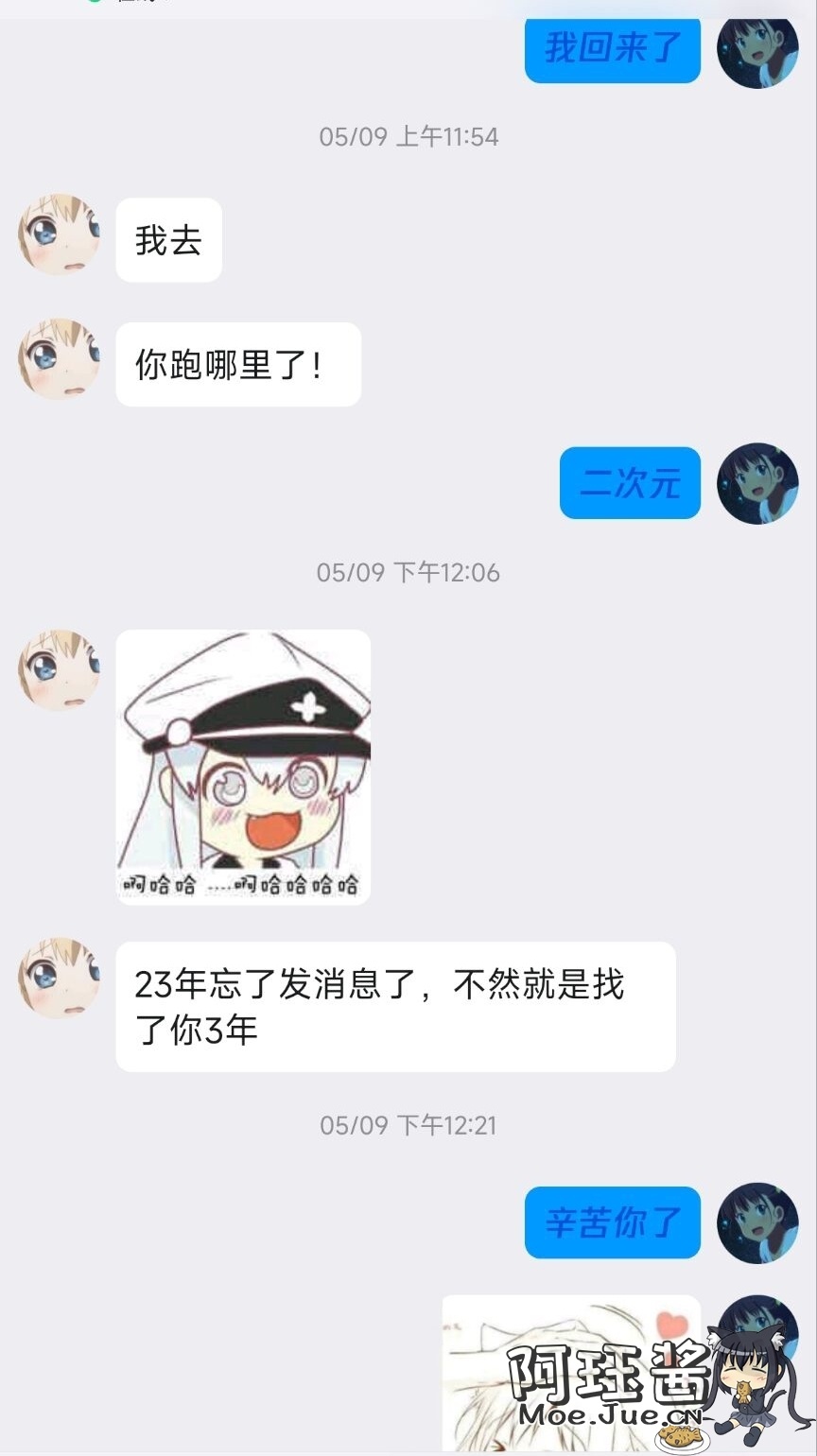
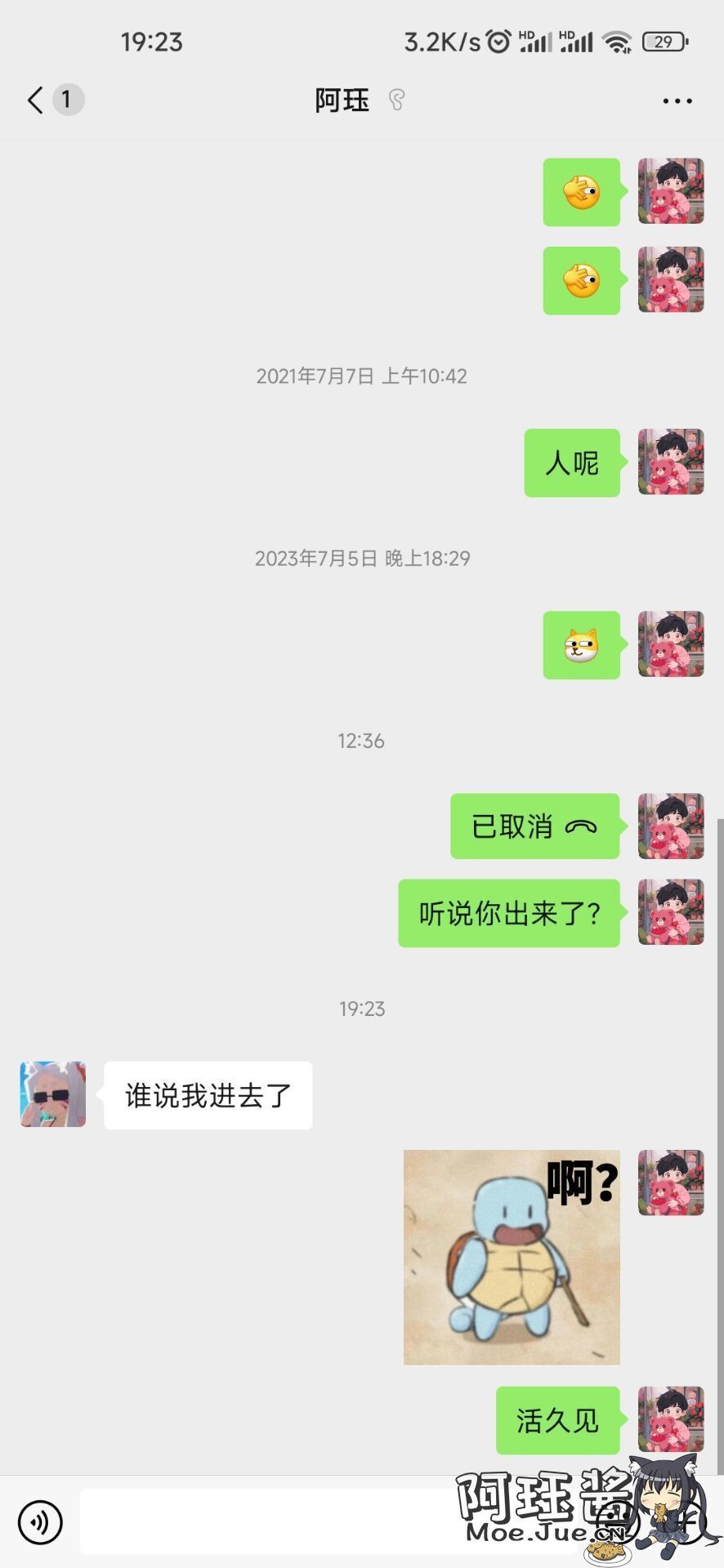
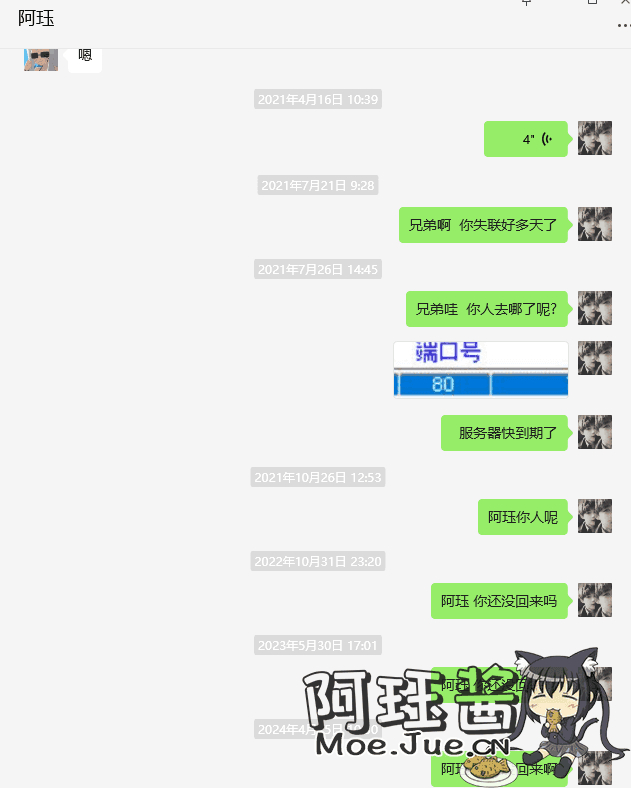
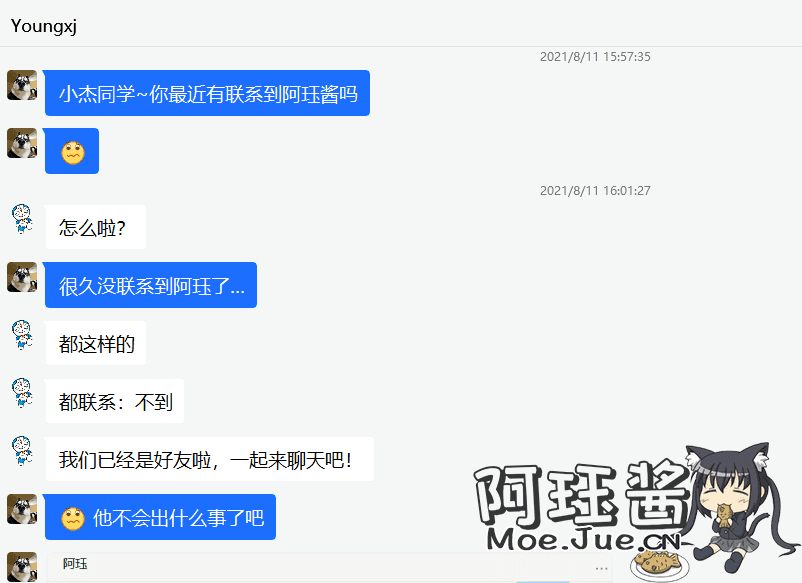
满世界的找我
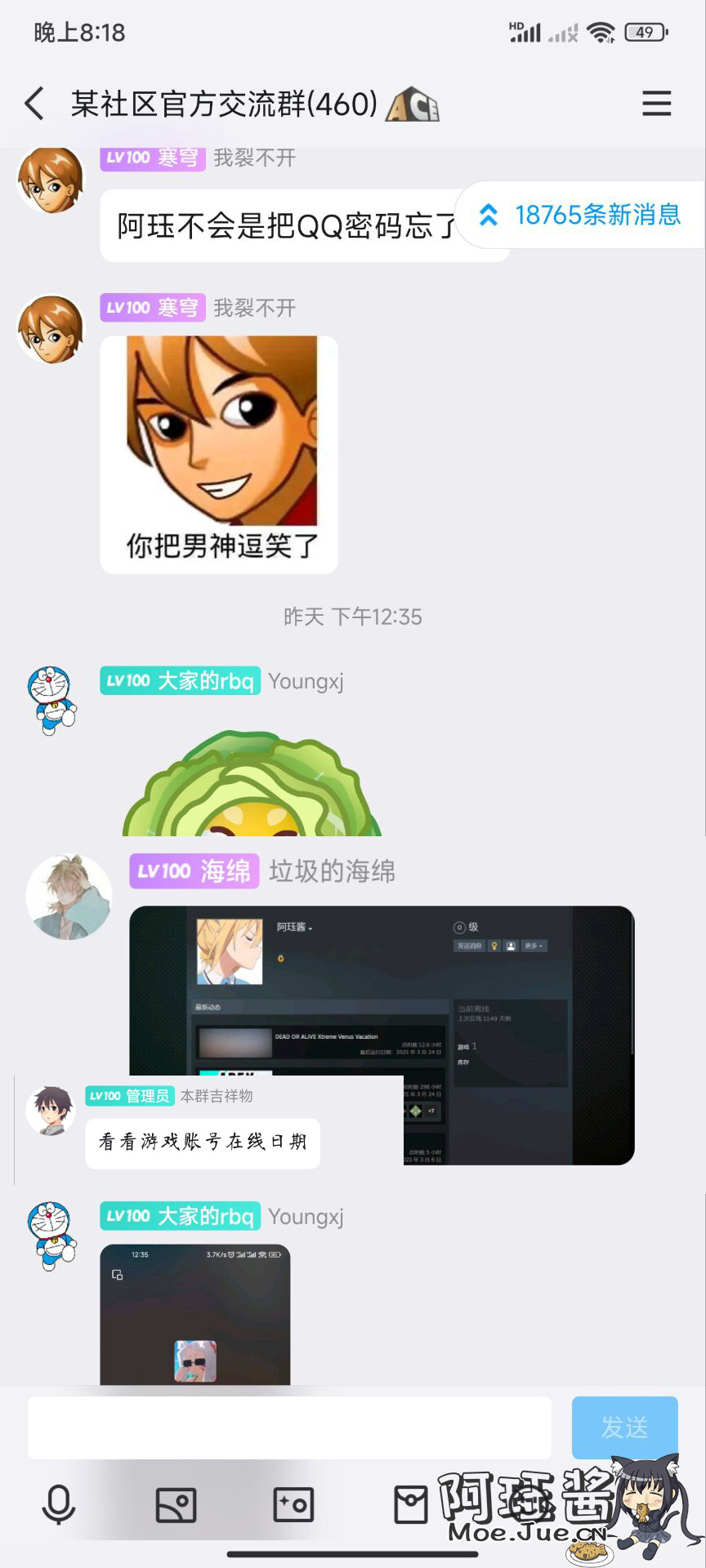
感动的不要不要的
下面才是正文
关于博客
博客首次建成时间是2016-06-09,如今已经成立了快8年之久了,在各种灾难中也顽强的生存了下来
期间也认识了好多好多的小伙伴,一起讨论,一起进步,一起成长。所以我并不想让博客就此消失

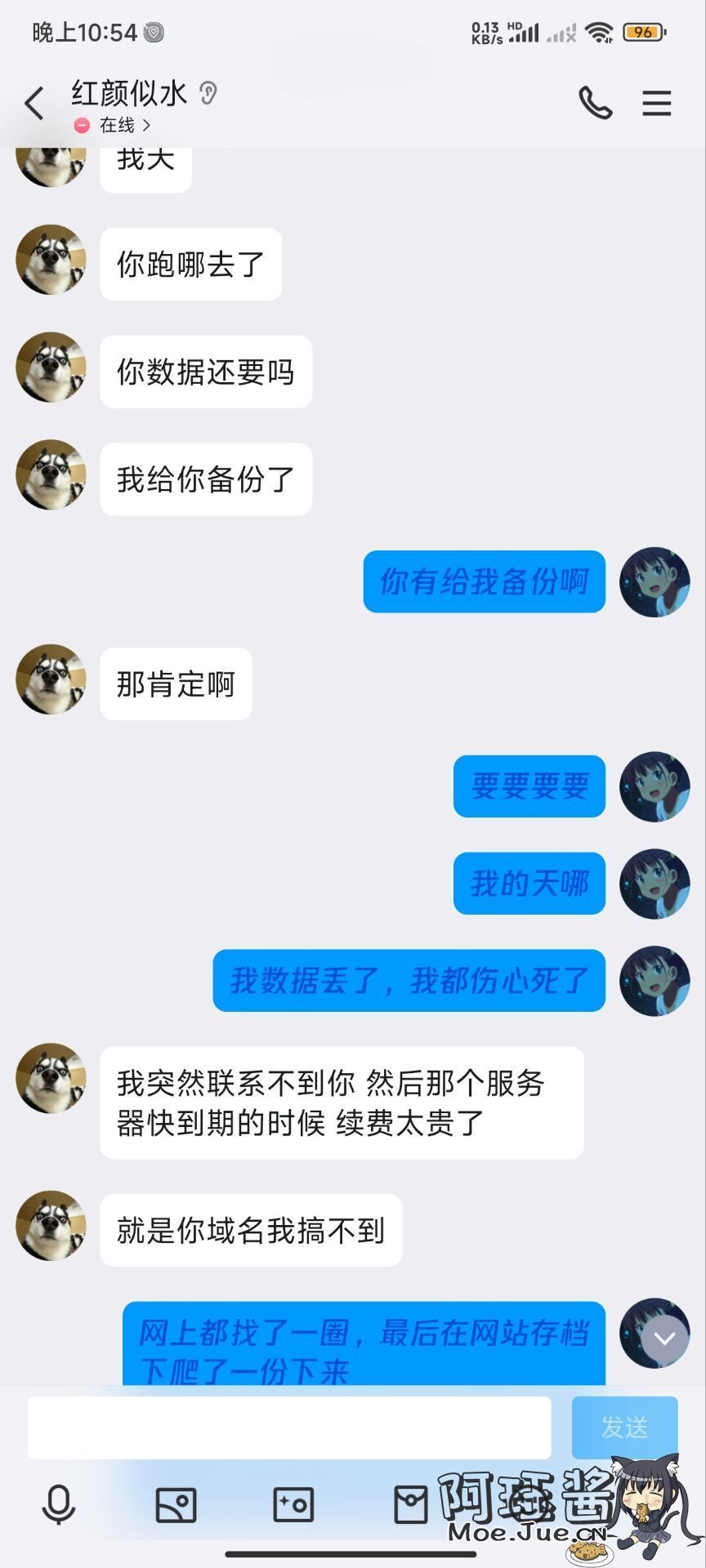
博客数据的原本有自动备份到七牛云的,但直到现在才知道,备份不知道什么原因,19年10月份左右就停掉了
都说互联网是有记忆的,本着“头可断血可流,数据不能丢”的精神,我在茫茫网络中寻找数日,终究还是让我找到了博客的网站存档。 可以点击这里去看我的博客历史版本archive (国外著名的网站档案馆项目)
于是就写了个Python脚本把文章和评论数据给爬下来了。
爬完后我发现有人已经给我备份了(我博客之前是别人赞助的三年)
博客搬迁
博客搬迁到博客园,其实也是不得已而为之
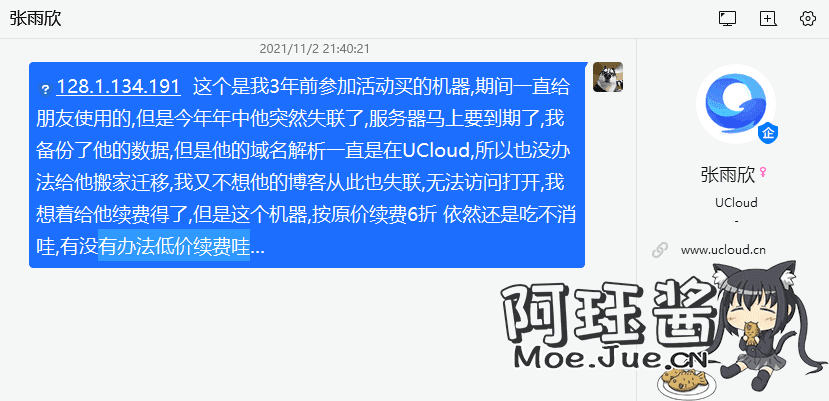
博客的原域名(52ecy.cn,moeins.cn,moeins.com)在到期后被人抢注,沟通无果后,一时半会是拿不回来的了
迫无无奈吧,只能暂且先将博客搬迁到博客园来(之后是否在自建的话再做打算吧)。另一面也可能是现在没有太多闲时间来折腾自己的系统,放在博客园反倒是更加省心省力。但是评论就没那么方便了,需要登录才可以发表评论,当然有啥问题也可以直接在群里@我
其实早在18年底的时候,我就已经有想换主题的想法了->这下真鸽了 (我可真能拖,太佩服我自己了)
无奈之前的emlog系统没有合适现成的,自己又懒着移植,便一直一拖再拖。
原来那个主题我一直就想换掉了,因为不太好看,没有个性,就是规规矩矩的,并不符合我的个性和风格
但是呢,我审美虽然特别棒,但你要让我自己写一套符合我审美的主题出来那就是有点困难了
后来突然看到博客园用户不忘编码的博客,心想博客园还支持这样自己美化。
一句“我又不想他博客从此也失联,无法访问打开” 后便决定暂时先搬迁到博客园再说吧。
一直就想换这种二次元风格的主题了
目前此博客美化风格样式基于樱花庄的白猫的WordPress主题Sakura,不忘编码移植,但BUG和细节问题较多,我又花了两天优化了一下,但也好多页面没优化,之后在慢慢来吧 (能明天在做的事为什么不留给明天的我去做呢)
由于之前的emlog博客使用的是HTML的TinyMCE编辑器,而且还是很老的版本,所以生成的文章的HTML代码也是相当的混乱,所以搬迁至博客园的markdown格式的时候出现了很多的样式不兼容问题,我也已经尽可能的修复了一些,当也没法保证所有文章都能正常的显示,看到的话再慢慢修吧
博客园不支持自建博客系统的一键搬迁功能,所以文章的发布时间和评论的信息就不能一同搬迁了,但我又想保留原汁原味,所以我就一并写到文章当中了,私密评论也还是隐藏了。
(自建博客系统的问题也和博客园团队沟通了,说后期开发会加上,也不为难他们了,他们也入不敷出了,文章的发布使用了Cnblog的VScode插件)
友情链接我也单独搞了一个页面给搬迁过去了,但也很多友链的网站也已经无法访问了,有的也已经下掉友链了。
现在的我也不是独立域名了,都不好意思再去申请友链了…..
之前博客的所有图片都是存在新浪的,一直担心哪天又给丢了,所以平常都是一份七牛云,一份新浪,现在也全部给搬迁到博客园来了
我为什么要写博客?
有人会觉得这些有这么重要吗?
有时候我也是想说点什么,想写点什么,但又没人说,没地方写,就是需要那么一个地方
我做博客也不是为了什么流量啊,赚钱之类的,就想搞一片自己的小天地,在自己的小圈子里瞎混哒
也许也正因这一份热爱,所以我才能慢慢坚持下来,奈何事与愿违,出了点意外
以前好多博客圈的朋友都要么不见了,要么都不更新了,真的好可惜啊,我都还没来得及认识他们 (尤其是月宅那货)
@寒穹 那货还说我:“阿珏,那么久了怎么还那么二刺螈”。
我想这么多年来,一直没变的就是我了吧。
很高兴,也很感谢还有那么多人记得我,对我那么好。

好像不该发这么多图片的
纪念逝去的博客,永远活在我的127里
Python代码
搬迁的Python的代码,虽然没啥用,但算是记录一下,供有需要的人学习学习
点击查看代码
“`
import os
import re
import time
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse, parse_qs
# 指定文件路径
file_path = "C:\\Users\\Administrator\\Desktop\\blog\\content.txt"
save_folder = "C:\\Users\\Administrator\\Desktop\\blog\\content\\"
def save_to_file(data, file_name):
try:
file_path = os.path.join(save_folder, file_name + ".txt")
with open(file_path, 'a', encoding='utf-8') as file:
file.write(data)
print("数据已成功保存到文件:", file_path)
except Exception as e:
print("保存文件时出错:", e)
def remove_html_tags(text):
soup = BeautifulSoup(text, 'html.parser')
return soup.get_text()
def comment(html_content):
comment_matches = re.findall(r'<div class="comment (.*?)" id="comment-\d+">[\s\S]*?<img .*?inal=".*?202.*?/([^"]+)"/>[\s\S]*?<div ' +
'class="comment-content">(.*?)</div>[\s\S]*?itle=".*?">(.*?)</span>[\s\S]*?<span class="comment-time">(.*?)</span>',
html_content, re.DOTALL)
article_comments = ''
if comment_matches:
i = 0
for comment_match in comment_matches:
if 'comment-children' in comment_match[0]:
i += 1
is_reply_comment = '>' * i
else:
is_reply_comment = '>'
i = 1
#头像 大小控制在40
# 兼容gravatar头像 https://secure.gravatar.com/avatar/
if 'gravatar.com' in comment_match[1]:
avatar_url = 's=\d+', '\\1s=40', str(comment_match[1]))) + ') '
else:
parsed_url = urlparse(comment_match[1])
query_params = parse_qs(parsed_url.query)
dst_uin = query_params.get('dst_uin', ['1638211921'])
avatar_url = '+'&s=40'+') '
comment_content = comment_match[2].strip()
nickname = comment_match[3].strip()
comment_time = comment_match[4].strip()
link_url = re.search(r'030.*?/(.*?)" .*? rel', nickname)
# 构造评论的markdown格式
comment_content = is_reply_comment + comment_content.replace('\n', '>')
comment_content = comment_content.replace('##这篇评论是私密评论##', '[#这篇评论是私密评论#]')
# 替换表情图片
soup = BeautifulSoup(comment_content, 'html.parser')
for img in soup.find_all('img'):
title_text = img.get('title', '')
img.replace_with('[#'+title_text+']')
comment_content = soup.get_text()
# 保存评论用户的URL地址
if link_url:
nickname = '['+remove_html_tags(nickname)+']'
link_url = '(' + link_url[1] + ') '
else:
link_url = ''
nickname = remove_html_tags(nickname) + ' '
if i == 1:
article_comments += '\n'
article_comments += is_reply_comment + avatar_url + nickname + link_url + comment_time + '\n' + comment_content + '\n'
return article_comments
else:
return ''
def process_article(url):
print("当前执行===="+url)
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
article_title = soup.find('h1', class_='article-title')
article_mate = soup.find('div', class_='article-meta')
article_article = soup.find('article', class_='article-content')
soup_content = BeautifulSoup(article_article.prettify(), 'html.parser')
img_tags = soup_content.find_all('img')
pattern = r"https://web.*?_/"
for img_tag in img_tags:
if 'data-original' in img_tag.attrs:
original_url = img_tag['data-original']
else:
original_url = img_tag['src']
cleaned_url = re.sub(pattern, '', original_url)
new_url = 'https://image.baidu.com/search/down?url=' + cleaned_url
img_tag['src'] = new_url
del img_tag['data-original']
article_comment = soup.find('div', class_='article_comment_list')
data = "###### `当你看到这个提示的时候,说明当前的文章是由原emlog博客系统搬迁至此的,文章发布时间已过于久远,编排和内容不一定完整,还请谅解`\n\n" + '###' + article_title.text.strip()+'\n\n'+article_mate.text.strip().replace('\n', '').replace('\r', '').replace('\t', '')+'\n' + soup_content.prettify().replace('<article class="article-content">', '').replace('</article>', '')
save_to_file(data + '\n网友评论:\n\n', article_title.text.strip())
data = comment(html_content)
if not data:
return
save_to_file(data, article_title.text.strip())
if article_comment:
comment_links = re.findall(r'<a\s+href="(.*?)nts"', str(article_comment))
if comment_links:
print('有分页评论数据')
for link in comment_links:
url = link +"nts"
print(url)
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
data = comment(html_content)
if not data:
return
save_to_file(data, article_title.text.strip())
print("写分页评论数据中")
else:
print("Failed to retrieve the webpage.")
def main():
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
segments = line.strip().split("—-")
if len(segments) > 0:
url = segments[0]
process_article(url)
else:
print("No URL found in the line.")
print('开启下一篇文章')
time.sleep(4)
if __name__ == "__main__":
main()
“`







